
![]()
クリエイティブカレッジは Yahoo! JAPAN と、ロクナナワークショップ が「 Yahoo! JAPAN インターネット クリエイティブアワード2009 」のプレイベントとして開催する1日限りの無料セミナーです。
マッシュアップ セッションは、1つめのセッションです。
開催概要
- 日程:7月10日(金)
- スケジュール:
14:00 – 15:00 マッシュアップ セッション
15:30 – 16:30 アニメーション セッション
17:00 – 18:00 コミュニケーション コンテンツ セッション
18:30 – 19:30 インスピレーション セッション - 出演者:山下達雄(Yahoo! JAPAN 研究所)
- 会場:東京・渋谷シアターTSUTAYA「 Prologue(プロローグ)」
- 料金:無料(事前申し込み必要)
ブログなどでご紹介いただく際のバナーをご用意いたしました。

イベントレポート
「 Yahoo! JAPAN × ロクナナワークショップ クリエイティブカレッジ 」の1つめのセッション、「 マッシュアップ セッション 」のレポートをお届けします。
本セッションでは、「Web APIを使ってテキストデータを魅せる!」というタイトルで、Yahoo! JAPAN研究所 の 山下達雄 氏をお招きしてお話を伺いました。
山下氏は、「 たつをの ChangeLog 」というブログを書いており、プログラミング技術やソフト、サイト紹介をしていらっしゃいます。ブログでご存知の方も多いのではないでしょうか?

[山下達雄氏]
内容は、テキスト解析系APIを使った形態素解析 と、ウェブ検索APIを使ったテキストマイニング についてです。
[形態素解析 -テキスト解析系API-]
1.形態素解析とは?
まずは、形態素解析とは何かについてお話いただきました。
形態素解析 (Morphological analysis) とは、与えられた文を形態素に分ける作業で、同時に形態素に、品詞や読みを付与します。
例)「書きました」→ 書き / まし / た
形態素解析を使うことによって、ウェブ上のテキストからタグクラウドを作ったり、プラスイメージのワードとマイナスイメージのワードでテキストを抽出することにより、評判検索をするといったようなことが可能になります。

[会場の様子]
形態素解析の中身として、辞書検索、最適パス探索、コスト最小法についての紹介がありました。詳しくは、山下氏が1999年にまとめられた資料にあります。
2.日本語形態素解析API
次に、Yahoo!が提供する日本語形態素解析APIについての説明がありました。

[山下達雄氏(左)]
「検索エンジンのインデックスのための形態素解析は、辞書のメンテナンスが肝になる。Yahoo!のテキスト解析APIは、日々ネット上に新しく登場する単語の収集を継続して行っている」(山下氏)
英語だとスペースで区切ることで単語に分けるのは容易ですが、日本語の文章はスペースで区切られていません。そのため、文章を解析して形態素に分解する必要があります。APIにリクエストを送ることで、XML形式でレスポンスが返ってきます。そのXMLを利用することで文章を形態素に分けることができるんですね。
例)庭 / に / は / 二 / 羽 / ニワトリ / が / いる
それぞれ、品詞がわかったり、漢字であれば読みを取得することも可能です。
面白いのが、「六本木」などの地名を入れるとそれが地名であることを解析してくれる点。XMLで地名ということがわかれば、そのデータをMAP系のAPIと連動して地図上に表示させるといったことが可能になります。
他には、読みがなをふる、関連語を抽出する、N-gram頻度調査、複合名詞(名詞連続)を取るといった例が紹介されました。
3.キーフレーズ抽出API
形態素解析の最後に、Yahoo!が提供するキーフレーズ抽出APIについての説明がありました。
キーフレーズ抽出APIとは、与えられた文章から、その文章を特徴づける重要な部分(キーフレーズ)を抽出し、独自の算出方法により点数付けを行って返すAPIです。
例えば、以下のような文章があるとすると、レスポンスは「東京ミッドタウン」「国立新美術館」「5分」と返ってきます。
「東京ミッドタウンから国立新美術館まで歩いて5分で着きます」
単語や助詞で細かく区切るのではなく、意味のまとまりのあるキーフレーズを文章から抽出してくれます。
例として、文章から地名となるキーフレーズを抽出し、その地名で画像検索をした結果を表示するサービスが紹介されました。

形態素解析についての説明が終了。
「見た目が地味なので、制作者にはどうしたら魅力的なコンテンツにできるかを考えてほしい」(山下氏)
[テキストマイニング -ウェブ検索API-]
形態素解析の次は、テキストマイニングについてのお話でした。
・ウェブ検索の基礎
まず、検索エンジンがどのような仕組みでテキストを収集しているのかについて説明がありました。クローラーがウェブページをとってきた後、インデクサが取ってきたウェブページからインデックスを作成する。それが繰り返されることで検索インデックスが作成される、といった内容でした。
・ウェブ検索API
次に、Yahoo!が提供するウェブ検索APIについての説明がありました。
ウェブ検索APIとは、APIにクエリーを投げることで、検索結果をXMLで返すプログラムのことです。一日のアクセス数は50,000回という制限があります。
Yahoo!デベロッパーネットワーク – 検索 – ウェブ検索
・検索によるテキストマイニング
最後に、ウェブ検索APIを利用したテキストマイニングの事例が紹介されました。コーパスとしての利用例(以下)、英語・日本語例文検索 といったものです。
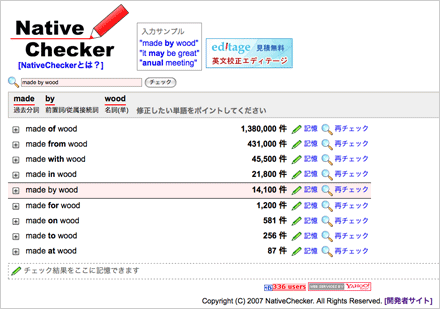
[Native Checker サイト]
Native Checker は、頻度の高い英語の使われ方を表示してくれる。
たくさんのデモを紹介しながら説明する山下氏。日々作ったサンプルをブログで紹介されています。
今回紹介してくださったデモの一覧は以下からご覧いただけます。
Yahoo!のテキスト解析系APIとウェブ検索APIの使い方についてのプレゼンで出てきた URLのリスト
他にも、人名と身長で検索をかけ、多数決と平均で人の想定される身長を取得する例や、うろおぼえなカタカナ単語から英単語のスペルを探す「uroboe」といったサービスが紹介されました。
山下氏には形態素解析とテキストマイニングについて、たくさんの事例を紹介しながら説明していただきました。APIを使うことで、欲しい情報をさっと取得し、コンテンツにしたりマッシュアップで組み合わせたりすることができます。本や雑誌など、今までアナログだったものがどんどんデジタルに変わって行く際に、テキスト系のシステム処理は今後も重要な要素になってくると感じました。
今回ご紹介いただいたサイトのURLは、ロクナナワークショップ ニュース でもご紹介しています。是非ご覧ください。
(2009/7/16 ロクナナワークショップ)
※セッション中にご紹介したサイト、内容は各著作者ならびに商標権保持者に帰属します。本ページの画像および文章の無断転載を禁止します。